Build your own neural network from scratch to solve handwritten digit (MNIST) classification problem
The quickest way to learn neural network is to start with Keras, an open source python library which provides easy-to-follow examples and well-documented functions. Keras is a well-known library which does not need an introduction. However, as I gained additional knowledge and become a machine learning practitioner, I felt uncomfortable about the fact that I did not even try to build my own neural network from scratch. This feeling of uneasiness made me to tackle a "hello world" of machine learning problem called, handwritten digit (MNIST) classification, on my own without any help from currently available machine learning frameworks. If you want to download code from github, click this link: https://github.com/jpark7ca/standard_neural_network Let's get started!
First, I am going to define the array structure for my neural network. To train a neural network with multiple training samples, simultaneously, I have decided to build it with multi-dimensional arrays (tensors of order 3) for input, weights and biases, and other intermediate arrays. It will be clearer when we actually dive into the code. Then, I am going to build a standard neural network with 3 layers. The first layer simply passes training features to the next layer which is the hidden layer of the network. The hidden layer learns features from training data, and then, pass the output generated from its neurons to the last layer which will eventually generates predictions.
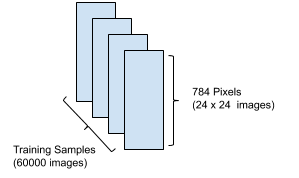
The MNIST data set contains 60,000 training and 10,000 test samples of "28 x 28" gray-scale pixel image, each of which represents a digit that can be ranged from 0 to 9. What the neural network tries to predict is a single-digit number of the input image. In order to feed 784 pixels (28x28) to the network for the training, I am going to convert each image into an array of 784 values and store all converted images into 2 tensors (multi-dimensional arrays) of the shape (60000, 784, 1) for training the network and (10000, 784, 1) for the testing. By the way, a special python library called numpy will be used since it supports multi-dimensional arrays (tensors) along with optimized mathematical functions.
To simplify the MNIST data import, I have created 2 files that can be easily imported into the array using Pickle python module. Each data label has already been converted to one hot-encoding vector. For example, the digit number 2 is represented in [0, 0, 1, 0, 0, 0, 0, 0, 0, 0], the digit 0 in [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] and so forth. The data structure is defined as follows.
mnist = {
'count': 60000,
'labels': labels,
'inputs': inputs
}
print mnist['inputs'].shape
print mnist['labels'].shape
----------------------------------
(60000, 784, 1)
(60000, 10, 1)
If you want to see how the image looks like, you can use matplotlib library to draw the digit stored in pixel values. The example below displays the first element in the training data set.
import matplotlib.pyplot as plt
...
rfile = open("mnist_train.pkl", "rb")
mnist = pickle.load(rfile)
rfile.close()
plt.imshow(mnist["inputs"][0].reshape(28, 28), interpolation='none')
print mnist["labels"][0]
plt.show()
----------------------------------
[[0.] [0.] [0.] [0.] [0.] [1.] [0.] [0.] [0.] [0.]]

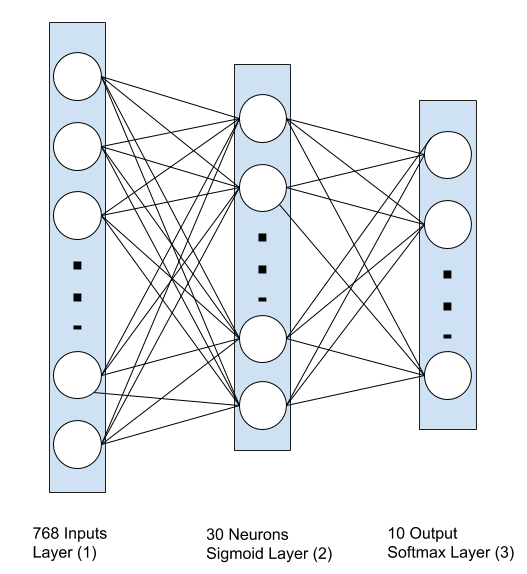
My neural network architecture consists of 3 layers, one input layer with 784 output neurons, a hidden layer with 30 neurons with sigmoid activation and lastly, a softmax layer with 10 neurons. The detailed explanation of how the neural network works (feed forward, cost calculation, back propagation and weights and biases update using gradient descent algorithm) will be omitted in this article in order to focus on the construction aspect of the network using python. For additional information, I suggest machine learning lectures from Geoffrey Hinton (theory-based) and Andrew Ng (practical approach). You can easily find their lectures in youtube or subscribe Coursera courses.
Each neuron in the hidden layer receives 768 features, a1 ~ 768 which are multiplied by own weights, w1 ~ 768 . Then, one biases term, b is added to produce the output, z. There are 30 neurons in the hidden layer, thus producing 30 z values as shown below.
z1 = w1*a1 + w2*a2 + ... + w768*a768 +b1
...
z30 = w1*a1 + w2*a2 + ... + w768*a768 +b30
For this hidden layer with 30 neurons, there are 768 weights and 1 bias per each neuron, resulting in 30 x 768 weights and 30 x 1 biases in total. This layer produces 30 outputs, each of which is the result of the non-linearity activation function called sigmoid, a(z). The calculated value, z above is fed to the sigmoid function as defined below:
sigmoid(z) = a(z) = 1 / (1 - exp(-z))
a1(z1) = output1
...
a30(z30) = output30
The formula above can also be expressed in vector notation, Z = Wtranspose . A + B, which is typically seen in machine learning literature.
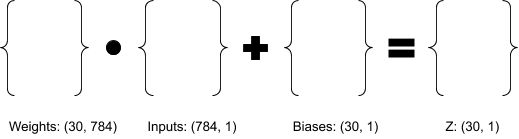
To calculate all 30 z values at once, I need to create a tensor of the shape (1, 30, 784) for weights and another tensor of the shape (1, 30, 1) for biases. As you have probably noticed that these tensors are shaped in such a way to calculate z values without transpose operation.
Keep in mind that all training samples (60,000) share the same weights and biases during the training (feed forward). The drawing below illustrates the shape of matrices involved in dot product and sum operation. So the resulting matrix, z will be of the shape (30, 1).
Wtranspose . A + B = Z
To calculate 60,000 training samples (inputs) simultaneously, both weights and inputs tensors need to be configured with (1, 30, 784) and (60000, 784, 1) respectively as shown below. During the dot product operation, the same weight tensor of (30, 784) will be used for all 60,000 training samples, thus producing a tensor (z) of the shape (60000, 30, 1). This can be easily done with numpy broadcasting which is an optimized way (done in C instead of python) of looping a dot product of two tensors, a weight tensor with each of 60,000 training samples.
By the way, the numpy broadcasting can also be used to add biases (1, 30, 1) to the resulting tensor (60000, 30, 1) of the dot product calculation. Therefore, the final z tensor with 60,000 training samples will be of the shape (60000, 30, 1).
I have created a python class to keep track of inputs, weights, biases, Zs, gradient weights and gradient biases (I will explain gradient tensors later), and outputs. Although I am using a hidden layer as an example, this class can be used for all layers of the network.
class FullyConnectedLayer:
def __init__(self, neurons, input=None, batch=None, activation=None):
self.outputsize = neurons # number of neurons
self.inputsize = input # number of input
self.batchsize = batch # batch size
self.activation = activation
self.z = None
self.a = None
self.g_weights = None
self.g_biases = None
To randomly initialize weights and biases in each layer, I have used a numpy random.randn function which generates numbers from the "standard normal" distribution. In this case, random.randn returns tensors (with random values) that are shaped by outputsize and inputsize parameters specified when the function is called. Since outputsize and inputsize of the hidden layer are 30 and 768, respectively, the weights tensor will be of (1, 30, 768) as an example.
# Initialize transposed(*) weights and biases if input defined.
self.weights = None if self.inputsize is None else np.random.randn(1, self.outputsize, self.inputsize)
self.biases = None if self.inputsize is None else np.random.randn(1, self.outputsize, 1)
During the training process, you can also specify the batch size which will be used to define the size of Zs (self.z), outputs (self.a) and gradient weights and biases tensors. Having a separate function (configure) to define the batch size in the layer class will be useful for re-configuring the network with various sizes. In this way, I can use different batch sizes (hyper-parameter) to improve the performance of the network using randomly generated small batch training approach, also commonly known as stochastic mini-batch gradient descent.
def configure(self, batch):
# set a batch size
self.batchsize = batch
self.z = None if self.inputsize is None else np.zeros(((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1))
self.a = np.zeros(((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1))
self.g_weights = None if self.inputsize is None else np.random.randn((self.batchsize if self.batchsize is not None else 1), self.outputsize, self.inputsize)
self.g_biases = None if self.inputsize is None else np.random.randn((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1)
Before diving into the training aspect of the neural network, let's me start with necessary steps to construct the standard network and load training data into the array. I am going to initialize the class, StandardNeuralNework with 3 layers. The first layer, which is also a fully connected layer, is the input layer, and it is configured with 784 neurons without any activation function. Not specifying the activation function in the layer description will tell the network to treat it as an input layer.
snn = StandardNeuralNetwork(network_layers_description=[["FullyConnected", 784, None], ["FullyConnected", 30, "sigmoid"], ["FullyConnected", 10, "softmax"]], cost="crossentropy")
As you can see, the second layer is defined with 30 neurons with sigmoid activation function. This fully connected layer is the hidden layer of the network, and its output will be fed to the last layer, which is defined with 10 neurons with softmax activation. Also, the cost function, "crossentropy", is specified in the network description. As you can guess, the output of the last layer is the prediction of the network, which indicates the predicted probability of what each output of the neuron suggests, in this case, a digit number 0 thru 9.
Once the network is defined, you can now load data stored in the file, mnist_train.pkl. Before assigning data to the input layer of the network, I am going to adjust the pixel value so that each pixel value can be ranged from 0.0 to 1.0 instead of 0 to 255; and the value will be of float type. By the way, I am going to split the training data into two, one (50,000 samples) for the training and another (10,000 samples) for the validation.
rfile = open("mnist_train.pkl", "rb")
mnist = pickle.load(rfile)
rfile.close()
inputs = (rescale_pixel((mnist["inputs"][0:50000]).astype('float32')), mnist["labels"][0:50000])
inputs_validation = (rescale_pixel((mnist["inputs"][50000:60000]).astype('float32')), mnist["labels"][50000:60000])
To train the network, you need to call execute function which takes inputs tensors (data and label), number of epochs, learning rate (eta), regularization parameter (lambda), and batch size. These parameters except inputs, also known as hyper-parameters, can be adjusted in order to improve the overall performance of the network. For an example, the regularization parameter (lambda) can be used to reduce data over-fitting, thus helping the network to generalize data in order to make better prediction for unseen hand-written digit images.
snn.execute(input=inputs, epochs=10, eta=3.0, _lambda=0, input_test=inputs_test, batch=50, debug=False)
Since my network needs to randomly generate mini-batches for the training (stochastic mini-batch gradient descent), this function first creates 1,000 mini-batches of size 50 samples from 50,000 training samples (1000 mini-batches = 50000 training samples / 50 batch size) per each epoch using random.shuffle function. Basically, the network will be trained with 1,000 mini-batches of randomly shuffled 50-samples in every epoch. Keep in mind that I have specified 10 epochs for the training; so the entire training consists of 10,000 iterations of 50-sample batch training. In this case, the training process can be understood as "updating weights and biases 10,000 times with gradient tensors (e.g., g_weights and g_biases) that are calculated from randomly generated 50-sample batch". I will explain the gradient tensors later.
idx = []
for i in xrange(0, num_data):
idx.append(i)
for e in xrange(0, epochs):
# shuffle
random.shuffle(idx)
idxbatches = [
idx[i:i+batch] for i in xrange(0, num_data, batch)
]
for index, idxbatch in enumerate(idxbatches):
inputbatch = None
labelbatch = None
for i in idxbatch:
if inputbatch is None:
inputbatch = input[0][i:i+1, 0:, 0:]
else:
inputbatch = np.append(inputbatch, input[0][i:i+1, 0:, 0:], axis=0)
if labelbatch is None:
labelbatch = input[1][i:i+1, 0:, 0:]
else:
labelbatch = np.append(labelbatch, input[1][i:i+1, 0:, 0:], axis=0)
self.run_batch((inputbatch, labelbatch), eta, _lambda, num_data, debug)
The actual training occurs in run_batch function. The training process consists of feed forward, cost calculation, back propagation and weights and biases updates, and it is repeated until learned (or converged). In machine learning literature, the word, convergence simply means that the difference between truth and prediction becomes close to zero (no mistake).
for index, layer in enumerate(self.layers):
if(layer.weights is None):
layer.a = a
else:
layer.z = np.matmul(layer.weights, a) + layer.biases
a = Activation.a(layer.activation)(layer.z)
layer.a = a
The feed forward is the first part of the training process that calculates Z = dot(Wtranspose , A) + B (linear function) ,where A is the input tensor, W and B are weights and biases tensors. Once calculated, this process feeds Z to the activation function, sigmoid(Z) to produce values, each of which can be between 0 and 1.
layer.z = np.matmul(layer.weights, a) + layer.biases
a = Activation.a(layer.activation)(layer.z)
layer.a = a
The first layer is the input layer which simply feeds input data to the next layer; weights and biases tensors are not used (None). By the way, the number of samples is 50 which is determined by the batch size of the network.
A layer1 = output layer1 = (50, 784, 1)
The hidden layer (30 neurons) calculates Z tensor which is the result of dot(Wtranspose , A) + B. All the shapes of tensors in this layers are listed below:
A layer1 = output layer1 = (50, 784, 1)
W layer2 = (1, 30, 784)
B layer2 = (1, 30, 1)
Z layer2 = (50, 30, 1)
And then, it feeds the tensor, Z to the sigmoid activation function. The resulting tensor from sigmoid operation, A, which is of the shape (50, 30, 1), will be fed to the last layer.
A layer2 = sigmoid(Z layer2) = (50, 30, 1)
The last layer also calculates Z, but instead of sigmoid, the softmax activation function is used to predict a digit number among 10 possible choices (0 ~ 9). The output value of softmax indicates the predicted probability of what each output of the neuron suggests, in this case, a digit number 0 thru 9. For an example, if the last layer outputs a vector with [0.01, 0.08, 0.01, 0.6, 0.01, 0.09, 0.02, 0.08, 0.012, 0.088], the network is suggesting that the probability of being a digit number 3 is 60%.
A layer2 = Output layer2 = (50, 30, 1)
W layer3 = (1, 10, 30)
B layer3 = (1, 10, 1)
Z layer3 = (50, 10, 1)
S layer3 = softmax(Z layer3) = (50, 10, 1)
The cost calculation is responsible for finding the mistake while comparing a ground truth (a known label) with a prediction (an output of the last layer), and the objective of the network is to minimize the mistake.
The detailed explanation of how the neural network works is beyond the scope of this article, but I just want to summarize the core idea so that the codes presented below make sense to those who are familiar with multivariate calculus and linear algebra. Instead of finding the minimum value of the cost function by equating the derivative of the function to zero (analytical approach in calculus), this machine learning technique tries to find the derivative of the cost function, precisely, partial derivatives of the function with respect to multiple parameters in iterative steps. The neural network is a representation of multiple linear functions (1st degree polynomial) and activation functions (non-linear functions) in a form of composite function. The neural network is linear in nature because weights and biases are parameters of linear functions (e.g., z1 = w1*a1 + w2*a2 + ... + w768*a768 +b1 ). Since I am processing multiple inputs (50 samples in my case) at once, the resulting gradients (weights and biases) are stored in gradient tensors. By the way, the opposite direction of gradient vector points to the steepest descent of the cost function, and since the objective is to find the minimum value, I can repeatedly update weights and biases (parameters) with a small value (a.k.a, learning rate) in the opposite direction of the gradient vector calculated with different training samples (inputs) in multiple iterations, thus gradually moving toward the minimum value of the cost function. This iterative process is also known as gradient descent. Keep in mind that the gradient descent algorithm is optimal when the cost function is convex. The convexity of the cost function is also beyond the scope of this article, but you can probably find a good explanation in google ;). You can use the chain rule of calculus to find partial derivatives of the cost function with respect to weights and biases located in multiple layers of the network since the network construction leading up to the cost function can be treated as a composite function. This process is called "back propagation" in machine learning literature.
The back propagation is part of the training process to calculate gradients (a.k.a., partial derivatives of the cost function with respect to weights and biases parameters) with an intention to change weights and biases, thus archiving better predictions for new digit images during inference (actual digit recognition task). Since the network uses crossentropy as a cost function, I need to find the derivative of the cost function with respect to Z layer3 first, which can be expressed as shown below.
If you want to find out why the derivative of the cost function with respect to z when the softmax is used in the last layer is s - y, you can check out my previous post, "Multiclass logistic regression (Softmax) and its derivative".
The equivalent codes of the formula above are listed below. By the way, I am using static functions here to use the same code for different cost functions but, the actual portion of the code responsible for the derivative is dcdz = a - y, where a is the output of the softmax function and y is the ground truth.
@staticmethod
def z_loss(type):
if type == "crossentropy":
return Cost.z_crossentropy
else:
return None
@staticmethod
def z_crossentropy(type, a, y):
dcdz = None
if type == "softmax":
dcdz = (a-y)
return dcdz
...
prevdz = Cost.z_loss(self.cost)(self.layers[i].activation, self.layers[i].a, y)
To find partial derivatives of the cost function with respect to biases and weights, see the codes below:
self.layers[i].g_biases = prevdz
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The reason, self.layers[i].g_biases = prevdz is that the derivative of Z with respect to b is 1 as shown below.
And to find out the gradient tensor for weights, the input values are multiplied by prevdz. By the way, the multiplication is an element-wise operation (hadamard product) in this case.
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The justification is shown as below:
Below is the back propagation portion of run_batch function:
for i in xrange(len(self.layers)-1, 0, -1):
if(i == len(self.layers)-1):
prevdz = Cost.z_loss(self.cost)(self.layers[i].activation, self.layers[i].a, y)
else:
prevda = np.matmul(np.transpose(self.layers[i+1].weights, (0, 2, 1)), prevdz)
prevdz = prevda * Activation.d_a(self.layers[i].activation)(self.layers[i].z)
self.layers[i].g_biases = prevdz
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The only thing left from here is to update weights and biases with a tiny step (learning rate: eta) toward the opposite direction (-) of gradients. Since I have calculated gradients with 50 samples (stored in g_weights and g_biases tensors), I am going to add all 50 gradients first and then, divide the sum by 50. As I mentioned previously, all training samples shared the same weights and biases during the training; so I am using the average values of gradient tensors calculated with 50 samples to update weights and biases tensors.
c_g_biases = self.layers[i].g_biases.sum(axis=0, keepdims=True)
c_g_weights = self.layers[i].g_weights.sum(axis=0, keepdims=True)
self.layers[i].biases = self.layers[i].biases - (eta/self.layers[i].batchsize) * c_g_biases
self.layers[i].weights = (1-(eta*(_lambda/num_data))) * self.layers[i].weights - (eta/self.layers[i].batchsize) * c_g_weights
Keep in mind that in the code above, the learning rate is divided by 50 (batch size) first and then, the resulting value is multiplied by the sum of gradients; for weights update, I have implemented L2 regularization to address data over-fitting issue.
Lastly, let me share with you another piece of code that helps me evaluate the network. I have added a function called, evaluate, which validates the accuracy of the network architecture after completing training in each epoch. The function basically evaluates network performance with 10,000 validation samples that I have previously set a side.
match = self.evaluate(input_test, debug)
total = input_test[0].shape[0]
print "Epoch {0}: Total Match: {1} Total Test Data: {2} ( {3}% )".format(e, match, total, (float(match)/float(total))*100.)
The entire walk-through of the training process is now complete. Let me share some observations while evaluating training sessions with different learning rates. If you change the learning rate to 2.0, you will notice that the accuracy will be improved, but slowly in each epoch compared to the learning rate set to 3.0. It means that the higher the learning rate, the quicker the convergence will occur, which makes sense since weights and biases are updated with a bit larger step toward the minimum of the cost function.
Building my own neural network from scratch was a quiet journey and an amazing experience! I strongly encourage readers to tackle this problem on your own. In fact, while preparing to write this article, I come to realize that the entire experience of building own neural network was really helpful to solidify my understanding of what I have been studying in the last few years. Happy Coding!
First, I am going to define the array structure for my neural network. To train a neural network with multiple training samples, simultaneously, I have decided to build it with multi-dimensional arrays (tensors of order 3) for input, weights and biases, and other intermediate arrays. It will be clearer when we actually dive into the code. Then, I am going to build a standard neural network with 3 layers. The first layer simply passes training features to the next layer which is the hidden layer of the network. The hidden layer learns features from training data, and then, pass the output generated from its neurons to the last layer which will eventually generates predictions.
The MNIST data set contains 60,000 training and 10,000 test samples of "28 x 28" gray-scale pixel image, each of which represents a digit that can be ranged from 0 to 9. What the neural network tries to predict is a single-digit number of the input image. In order to feed 784 pixels (28x28) to the network for the training, I am going to convert each image into an array of 784 values and store all converted images into 2 tensors (multi-dimensional arrays) of the shape (60000, 784, 1) for training the network and (10000, 784, 1) for the testing. By the way, a special python library called numpy will be used since it supports multi-dimensional arrays (tensors) along with optimized mathematical functions.
To simplify the MNIST data import, I have created 2 files that can be easily imported into the array using Pickle python module. Each data label has already been converted to one hot-encoding vector. For example, the digit number 2 is represented in [0, 0, 1, 0, 0, 0, 0, 0, 0, 0], the digit 0 in [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] and so forth. The data structure is defined as follows.
mnist = {
'count': 60000,
'labels': labels,
'inputs': inputs
}
print mnist['inputs'].shape
print mnist['labels'].shape
----------------------------------
(60000, 784, 1)
(60000, 10, 1)
If you want to see how the image looks like, you can use matplotlib library to draw the digit stored in pixel values. The example below displays the first element in the training data set.
import matplotlib.pyplot as plt
...
rfile = open("mnist_train.pkl", "rb")
mnist = pickle.load(rfile)
rfile.close()
plt.imshow(mnist["inputs"][0].reshape(28, 28), interpolation='none')
print mnist["labels"][0]
plt.show()
----------------------------------
[[0.] [0.] [0.] [0.] [0.] [1.] [0.] [0.] [0.] [0.]]
Each neuron in the hidden layer receives 768 features, a1 ~ 768 which are multiplied by own weights, w1 ~ 768 . Then, one biases term, b is added to produce the output, z. There are 30 neurons in the hidden layer, thus producing 30 z values as shown below.
z1 = w1*a1 + w2*a2 + ... + w768*a768 +b1
...
z30 = w1*a1 + w2*a2 + ... + w768*a768 +b30
For this hidden layer with 30 neurons, there are 768 weights and 1 bias per each neuron, resulting in 30 x 768 weights and 30 x 1 biases in total. This layer produces 30 outputs, each of which is the result of the non-linearity activation function called sigmoid, a(z). The calculated value, z above is fed to the sigmoid function as defined below:
sigmoid(z) = a(z) = 1 / (1 - exp(-z))
a1(z1) = output1
...
a30(z30) = output30
The formula above can also be expressed in vector notation, Z = Wtranspose . A + B, which is typically seen in machine learning literature.
To calculate all 30 z values at once, I need to create a tensor of the shape (1, 30, 784) for weights and another tensor of the shape (1, 30, 1) for biases. As you have probably noticed that these tensors are shaped in such a way to calculate z values without transpose operation.
Keep in mind that all training samples (60,000) share the same weights and biases during the training (feed forward). The drawing below illustrates the shape of matrices involved in dot product and sum operation. So the resulting matrix, z will be of the shape (30, 1).
Wtranspose . A + B = Z
To calculate 60,000 training samples (inputs) simultaneously, both weights and inputs tensors need to be configured with (1, 30, 784) and (60000, 784, 1) respectively as shown below. During the dot product operation, the same weight tensor of (30, 784) will be used for all 60,000 training samples, thus producing a tensor (z) of the shape (60000, 30, 1). This can be easily done with numpy broadcasting which is an optimized way (done in C instead of python) of looping a dot product of two tensors, a weight tensor with each of 60,000 training samples.
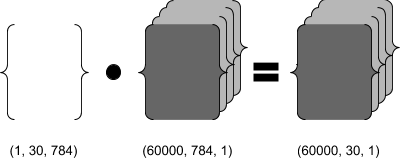
By the way, the numpy broadcasting can also be used to add biases (1, 30, 1) to the resulting tensor (60000, 30, 1) of the dot product calculation. Therefore, the final z tensor with 60,000 training samples will be of the shape (60000, 30, 1).
I have created a python class to keep track of inputs, weights, biases, Zs, gradient weights and gradient biases (I will explain gradient tensors later), and outputs. Although I am using a hidden layer as an example, this class can be used for all layers of the network.
class FullyConnectedLayer:
def __init__(self, neurons, input=None, batch=None, activation=None):
self.outputsize = neurons # number of neurons
self.inputsize = input # number of input
self.batchsize = batch # batch size
self.activation = activation
self.z = None
self.a = None
self.g_weights = None
self.g_biases = None
To randomly initialize weights and biases in each layer, I have used a numpy random.randn function which generates numbers from the "standard normal" distribution. In this case, random.randn returns tensors (with random values) that are shaped by outputsize and inputsize parameters specified when the function is called. Since outputsize and inputsize of the hidden layer are 30 and 768, respectively, the weights tensor will be of (1, 30, 768) as an example.
# Initialize transposed(*) weights and biases if input defined.
self.weights = None if self.inputsize is None else np.random.randn(1, self.outputsize, self.inputsize)
self.biases = None if self.inputsize is None else np.random.randn(1, self.outputsize, 1)
During the training process, you can also specify the batch size which will be used to define the size of Zs (self.z), outputs (self.a) and gradient weights and biases tensors. Having a separate function (configure) to define the batch size in the layer class will be useful for re-configuring the network with various sizes. In this way, I can use different batch sizes (hyper-parameter) to improve the performance of the network using randomly generated small batch training approach, also commonly known as stochastic mini-batch gradient descent.
def configure(self, batch):
# set a batch size
self.batchsize = batch
self.z = None if self.inputsize is None else np.zeros(((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1))
self.a = np.zeros(((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1))
self.g_weights = None if self.inputsize is None else np.random.randn((self.batchsize if self.batchsize is not None else 1), self.outputsize, self.inputsize)
self.g_biases = None if self.inputsize is None else np.random.randn((self.batchsize if self.batchsize is not None else 1), self.outputsize, 1)
Before diving into the training aspect of the neural network, let's me start with necessary steps to construct the standard network and load training data into the array. I am going to initialize the class, StandardNeuralNework with 3 layers. The first layer, which is also a fully connected layer, is the input layer, and it is configured with 784 neurons without any activation function. Not specifying the activation function in the layer description will tell the network to treat it as an input layer.
snn = StandardNeuralNetwork(network_layers_description=[["FullyConnected", 784, None], ["FullyConnected", 30, "sigmoid"], ["FullyConnected", 10, "softmax"]], cost="crossentropy")
As you can see, the second layer is defined with 30 neurons with sigmoid activation function. This fully connected layer is the hidden layer of the network, and its output will be fed to the last layer, which is defined with 10 neurons with softmax activation. Also, the cost function, "crossentropy", is specified in the network description. As you can guess, the output of the last layer is the prediction of the network, which indicates the predicted probability of what each output of the neuron suggests, in this case, a digit number 0 thru 9.
Once the network is defined, you can now load data stored in the file, mnist_train.pkl. Before assigning data to the input layer of the network, I am going to adjust the pixel value so that each pixel value can be ranged from 0.0 to 1.0 instead of 0 to 255; and the value will be of float type. By the way, I am going to split the training data into two, one (50,000 samples) for the training and another (10,000 samples) for the validation.
rfile = open("mnist_train.pkl", "rb")
mnist = pickle.load(rfile)
rfile.close()
inputs = (rescale_pixel((mnist["inputs"][0:50000]).astype('float32')), mnist["labels"][0:50000])
inputs_validation = (rescale_pixel((mnist["inputs"][50000:60000]).astype('float32')), mnist["labels"][50000:60000])
To train the network, you need to call execute function which takes inputs tensors (data and label), number of epochs, learning rate (eta), regularization parameter (lambda), and batch size. These parameters except inputs, also known as hyper-parameters, can be adjusted in order to improve the overall performance of the network. For an example, the regularization parameter (lambda) can be used to reduce data over-fitting, thus helping the network to generalize data in order to make better prediction for unseen hand-written digit images.
snn.execute(input=inputs, epochs=10, eta=3.0, _lambda=0, input_test=inputs_test, batch=50, debug=False)
Since my network needs to randomly generate mini-batches for the training (stochastic mini-batch gradient descent), this function first creates 1,000 mini-batches of size 50 samples from 50,000 training samples (1000 mini-batches = 50000 training samples / 50 batch size) per each epoch using random.shuffle function. Basically, the network will be trained with 1,000 mini-batches of randomly shuffled 50-samples in every epoch. Keep in mind that I have specified 10 epochs for the training; so the entire training consists of 10,000 iterations of 50-sample batch training. In this case, the training process can be understood as "updating weights and biases 10,000 times with gradient tensors (e.g., g_weights and g_biases) that are calculated from randomly generated 50-sample batch". I will explain the gradient tensors later.
idx = []
for i in xrange(0, num_data):
idx.append(i)
for e in xrange(0, epochs):
# shuffle
random.shuffle(idx)
idxbatches = [
idx[i:i+batch] for i in xrange(0, num_data, batch)
]
for index, idxbatch in enumerate(idxbatches):
inputbatch = None
labelbatch = None
for i in idxbatch:
if inputbatch is None:
inputbatch = input[0][i:i+1, 0:, 0:]
else:
inputbatch = np.append(inputbatch, input[0][i:i+1, 0:, 0:], axis=0)
if labelbatch is None:
labelbatch = input[1][i:i+1, 0:, 0:]
else:
labelbatch = np.append(labelbatch, input[1][i:i+1, 0:, 0:], axis=0)
self.run_batch((inputbatch, labelbatch), eta, _lambda, num_data, debug)
The actual training occurs in run_batch function. The training process consists of feed forward, cost calculation, back propagation and weights and biases updates, and it is repeated until learned (or converged). In machine learning literature, the word, convergence simply means that the difference between truth and prediction becomes close to zero (no mistake).
for index, layer in enumerate(self.layers):
if(layer.weights is None):
layer.a = a
else:
layer.z = np.matmul(layer.weights, a) + layer.biases
a = Activation.a(layer.activation)(layer.z)
layer.a = a
The feed forward is the first part of the training process that calculates Z = dot(Wtranspose , A) + B (linear function) ,where A is the input tensor, W and B are weights and biases tensors. Once calculated, this process feeds Z to the activation function, sigmoid(Z) to produce values, each of which can be between 0 and 1.
layer.z = np.matmul(layer.weights, a) + layer.biases
a = Activation.a(layer.activation)(layer.z)
layer.a = a
The first layer is the input layer which simply feeds input data to the next layer; weights and biases tensors are not used (None). By the way, the number of samples is 50 which is determined by the batch size of the network.
A layer1 = output layer1 = (50, 784, 1)
The hidden layer (30 neurons) calculates Z tensor which is the result of dot(Wtranspose , A) + B. All the shapes of tensors in this layers are listed below:
A layer1 = output layer1 = (50, 784, 1)
W layer2 = (1, 30, 784)
B layer2 = (1, 30, 1)
Z layer2 = (50, 30, 1)
And then, it feeds the tensor, Z to the sigmoid activation function. The resulting tensor from sigmoid operation, A, which is of the shape (50, 30, 1), will be fed to the last layer.
A layer2 = sigmoid(Z layer2) = (50, 30, 1)
The last layer also calculates Z, but instead of sigmoid, the softmax activation function is used to predict a digit number among 10 possible choices (0 ~ 9). The output value of softmax indicates the predicted probability of what each output of the neuron suggests, in this case, a digit number 0 thru 9. For an example, if the last layer outputs a vector with [0.01, 0.08, 0.01, 0.6, 0.01, 0.09, 0.02, 0.08, 0.012, 0.088], the network is suggesting that the probability of being a digit number 3 is 60%.
A layer2 = Output layer2 = (50, 30, 1)
W layer3 = (1, 10, 30)
B layer3 = (1, 10, 1)
Z layer3 = (50, 10, 1)
S layer3 = softmax(Z layer3) = (50, 10, 1)
The cost calculation is responsible for finding the mistake while comparing a ground truth (a known label) with a prediction (an output of the last layer), and the objective of the network is to minimize the mistake.
The detailed explanation of how the neural network works is beyond the scope of this article, but I just want to summarize the core idea so that the codes presented below make sense to those who are familiar with multivariate calculus and linear algebra. Instead of finding the minimum value of the cost function by equating the derivative of the function to zero (analytical approach in calculus), this machine learning technique tries to find the derivative of the cost function, precisely, partial derivatives of the function with respect to multiple parameters in iterative steps. The neural network is a representation of multiple linear functions (1st degree polynomial) and activation functions (non-linear functions) in a form of composite function. The neural network is linear in nature because weights and biases are parameters of linear functions (e.g., z1 = w1*a1 + w2*a2 + ... + w768*a768 +b1 ). Since I am processing multiple inputs (50 samples in my case) at once, the resulting gradients (weights and biases) are stored in gradient tensors. By the way, the opposite direction of gradient vector points to the steepest descent of the cost function, and since the objective is to find the minimum value, I can repeatedly update weights and biases (parameters) with a small value (a.k.a, learning rate) in the opposite direction of the gradient vector calculated with different training samples (inputs) in multiple iterations, thus gradually moving toward the minimum value of the cost function. This iterative process is also known as gradient descent. Keep in mind that the gradient descent algorithm is optimal when the cost function is convex. The convexity of the cost function is also beyond the scope of this article, but you can probably find a good explanation in google ;). You can use the chain rule of calculus to find partial derivatives of the cost function with respect to weights and biases located in multiple layers of the network since the network construction leading up to the cost function can be treated as a composite function. This process is called "back propagation" in machine learning literature.
The back propagation is part of the training process to calculate gradients (a.k.a., partial derivatives of the cost function with respect to weights and biases parameters) with an intention to change weights and biases, thus archiving better predictions for new digit images during inference (actual digit recognition task). Since the network uses crossentropy as a cost function, I need to find the derivative of the cost function with respect to Z layer3 first, which can be expressed as shown below.

If you want to find out why the derivative of the cost function with respect to z when the softmax is used in the last layer is s - y, you can check out my previous post, "Multiclass logistic regression (Softmax) and its derivative".
The equivalent codes of the formula above are listed below. By the way, I am using static functions here to use the same code for different cost functions but, the actual portion of the code responsible for the derivative is dcdz = a - y, where a is the output of the softmax function and y is the ground truth.
@staticmethod
def z_loss(type):
if type == "crossentropy":
return Cost.z_crossentropy
else:
return None
@staticmethod
def z_crossentropy(type, a, y):
dcdz = None
if type == "softmax":
dcdz = (a-y)
return dcdz
...
prevdz = Cost.z_loss(self.cost)(self.layers[i].activation, self.layers[i].a, y)
To find partial derivatives of the cost function with respect to biases and weights, see the codes below:
self.layers[i].g_biases = prevdz
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The reason, self.layers[i].g_biases = prevdz is that the derivative of Z with respect to b is 1 as shown below.
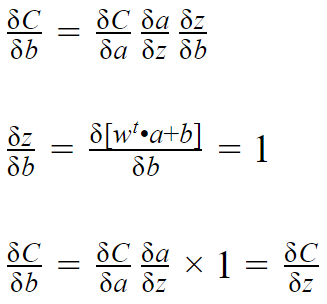
And to find out the gradient tensor for weights, the input values are multiplied by prevdz. By the way, the multiplication is an element-wise operation (hadamard product) in this case.
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The justification is shown as below:

Below is the back propagation portion of run_batch function:
for i in xrange(len(self.layers)-1, 0, -1):
if(i == len(self.layers)-1):
prevdz = Cost.z_loss(self.cost)(self.layers[i].activation, self.layers[i].a, y)
else:
prevda = np.matmul(np.transpose(self.layers[i+1].weights, (0, 2, 1)), prevdz)
prevdz = prevda * Activation.d_a(self.layers[i].activation)(self.layers[i].z)
self.layers[i].g_biases = prevdz
self.layers[i].g_weights = np.matmul(prevdz, np.transpose(self.layers[i-1].a, (0, 2, 1)))
The only thing left from here is to update weights and biases with a tiny step (learning rate: eta) toward the opposite direction (-) of gradients. Since I have calculated gradients with 50 samples (stored in g_weights and g_biases tensors), I am going to add all 50 gradients first and then, divide the sum by 50. As I mentioned previously, all training samples shared the same weights and biases during the training; so I am using the average values of gradient tensors calculated with 50 samples to update weights and biases tensors.
c_g_biases = self.layers[i].g_biases.sum(axis=0, keepdims=True)
c_g_weights = self.layers[i].g_weights.sum(axis=0, keepdims=True)
self.layers[i].weights = (1-(eta*(_lambda/num_data))) * self.layers[i].weights - (eta/self.layers[i].batchsize) * c_g_weights
Keep in mind that in the code above, the learning rate is divided by 50 (batch size) first and then, the resulting value is multiplied by the sum of gradients; for weights update, I have implemented L2 regularization to address data over-fitting issue.
Lastly, let me share with you another piece of code that helps me evaluate the network. I have added a function called, evaluate, which validates the accuracy of the network architecture after completing training in each epoch. The function basically evaluates network performance with 10,000 validation samples that I have previously set a side.
match = self.evaluate(input_test, debug)
total = input_test[0].shape[0]
print "Epoch {0}: Total Match: {1} Total Test Data: {2} ( {3}% )".format(e, match, total, (float(match)/float(total))*100.)
The entire walk-through of the training process is now complete. Let me share some observations while evaluating training sessions with different learning rates. If you change the learning rate to 2.0, you will notice that the accuracy will be improved, but slowly in each epoch compared to the learning rate set to 3.0. It means that the higher the learning rate, the quicker the convergence will occur, which makes sense since weights and biases are updated with a bit larger step toward the minimum of the cost function.
Building my own neural network from scratch was a quiet journey and an amazing experience! I strongly encourage readers to tackle this problem on your own. In fact, while preparing to write this article, I come to realize that the entire experience of building own neural network was really helpful to solidify my understanding of what I have been studying in the last few years. Happy Coding!
Comments
Post a Comment